
कमिंस QSK डीजल इंजन पार्ट्स के लिए दबाव सेंसर 3408560


विवरण
विपणन प्रकार:हॉट प्रोडक्ट 2019
उत्पत्ति का स्थान:झेजियांग, चीन
ब्रांड का नाम:फ्लाइंग बैल
वारंटी:1 वर्ष
भाग संख्या:3408560
प्रकार:दाबानुकूलित संवेदक
गुणवत्ता:उच्च गुणवत्ता
बिक्री के बाद सेवा प्रदान की गई:ऑनलाइन समर्थन
पैकिंग:तटस्थ पैकिंग
डिलीवरी का समय:5-15 दिन
उत्पाद परिचय
विभिन्न डेटा प्रोसेसिंग विधियों के अनुसार, सूचना संलयन प्रणाली के तीन आर्किटेक्चर हैं: वितरित, केंद्रीकृत और हाइब्रिड।
1) वितरित: सबसे पहले, स्वतंत्र सेंसर द्वारा प्राप्त मूल डेटा को स्थानीय रूप से संसाधित किया जाता है, और फिर परिणाम अंतिम परिणाम प्राप्त करने के लिए बुद्धिमान अनुकूलन और संयोजन के लिए सूचना फ्यूजन सेंटर को भेजे जाते हैं। वितरित में संचार बैंडविड्थ, तेजी से गणना की गति, अच्छी विश्वसनीयता और निरंतरता की कम मांग है, लेकिन ट्रैकिंग सटीकता केंद्रीकृत एक की तुलना में बहुत कम है। वितरित संलयन संरचना को प्रतिक्रिया के साथ वितरित संलयन संरचना में विभाजित किया जा सकता है और प्रतिक्रिया के बिना वितरित संलयन संरचना।
2) केंद्रीकरण: केंद्रीकरण प्रत्येक सेंसर द्वारा प्राप्त कच्चे डेटा को सीधे फ्यूजन प्रोसेसिंग के लिए केंद्रीय प्रोसेसर को भेजता है, जो वास्तविक समय के संलयन का एहसास कर सकता है। इसकी डेटा प्रोसेसिंग सटीकता अधिक है और इसका एल्गोरिथ्म लचीला है, लेकिन इसके नुकसान प्रोसेसर, कम विश्वसनीयता और बड़ी डेटा वॉल्यूम के लिए उच्च आवश्यकताएं हैं, इसलिए इसे महसूस करना मुश्किल है;
3) हाइब्रिड: हाइब्रिड मल्टी-सेंसर सूचना फ्यूजन फ्रेमवर्क में, कुछ सेंसर केंद्रीकृत फ्यूजन मोड को अपनाते हैं, और बाकी ने वितरित फ्यूजन मोड को अपनाया। हाइब्रिड फ्यूजन फ्रेमवर्क में मजबूत अनुकूलन क्षमता है, केंद्रीकृत संलयन और वितरण के लाभों को ध्यान में रखता है, और मजबूत स्थिरता है। हाइब्रिड फ्यूजन मोड की संरचना पहले दो फ्यूजन मोड की तुलना में अधिक जटिल है, जो संचार और गणना की लागत को बढ़ाती है।
कल्मन फिल्टर (केएफ)
कलमन फ़िल्टर द्वारा सूचना प्रसंस्करण की प्रक्रिया आम तौर पर भविष्यवाणी और सुधार है। यह न केवल एक सरल और ठोस एल्गोरिथ्म है, बल्कि मल्टी-सेंसर सूचना संलयन प्रौद्योगिकी की भूमिका में एक बहुत ही उपयोगी सिस्टम प्रसंस्करण योजना भी है। वास्तव में, यह सूचना डेटा को संसाधित करने के कई प्रणालियों के तरीकों के समान है। यह गणितीय पुनरावृत्ति पुनरावर्ती गणना के माध्यम से फ्यूज्ड डेटा के लिए एक प्रभावी सांख्यिकीय इष्टतम अनुमान प्रदान करता है, लेकिन इसके लिए थोड़ा भंडारण स्थान और गणना की आवश्यकता होती है, इसलिए यह सीमित डेटा प्रोसेसिंग स्पेस और स्पीड के साथ पर्यावरण के लिए उपयुक्त है। KF को दो प्रकारों में विभाजित किया जा सकता है: वितरित कलमन फ़िल्टर (DKF) और विस्तारित कलमन फ़िल्टर (EKF)। DKF डेटा फ्यूजन को पूरी तरह से विकेंद्रीकृत कर सकता है, जबकि EKF प्रभावी रूप से सूचना संलयन प्रक्रिया पर डेटा प्रोसेसिंग त्रुटियों और अस्थिरता के प्रभाव को दूर कर सकता है।
उत्पाद की तस्वीर

कंपनी का विवरण







कंपनी का लाभ
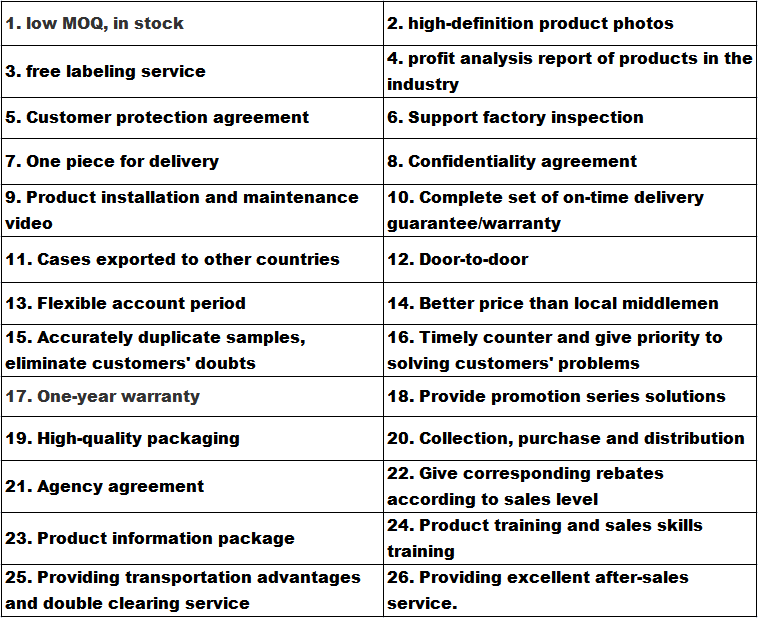
परिवहन

उपवास

संबंधित उत्पाद








